How we achieved a 3x faster song analysis
BpmDj's achilles heel is the slow analysis. If you have 60 minutes music you spend around 20 minutes analyzing it. Allthough this is already three times faster than realtime, from a user experience point of view it is too long.
Luckily, we just updated the analysis core so that it runs three times as fast as before. The result is that the analysis runs now about nine times faster than realtime. Nevertheless, it is still a long waiting time. If you have an hour of music, you can watch paint dry for about 6 minutes.
This post focuses on how this speedup was obtained
How the analysis pipeline worked
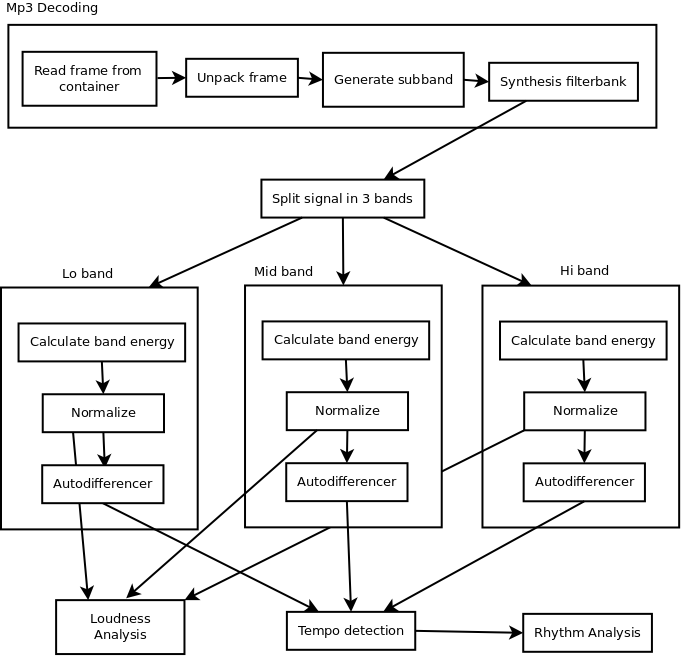
The analysis process in the past consisted of a number of steps, starting with -of course- the mp3 decoder. That process itself consists of retrieving data from disk, unpacking frames (these are huffmann coded), then generating subband data, which is then sent into a synthesis filterbank that will generate the time domain data.
From there BpmDj would split the signal in three bands. Each band would be processed to obtain the energy, which was then normalized and send into an autodifferencer.
Once all data is processed, tempo detection commences, after which rhythm information can be obtained.
On the side also loudness information is gathered and stored.
Mp3 and subband coding
Of course, if you look at the above schematics, it is clear that the mp3 decoder converts data from the frequency domain to the time domain, to then again convert it to a frequency domain. That felt like a huge waste of time. The problem of course is obtaineing and understanding the intermediate data. The new schema would be as follows
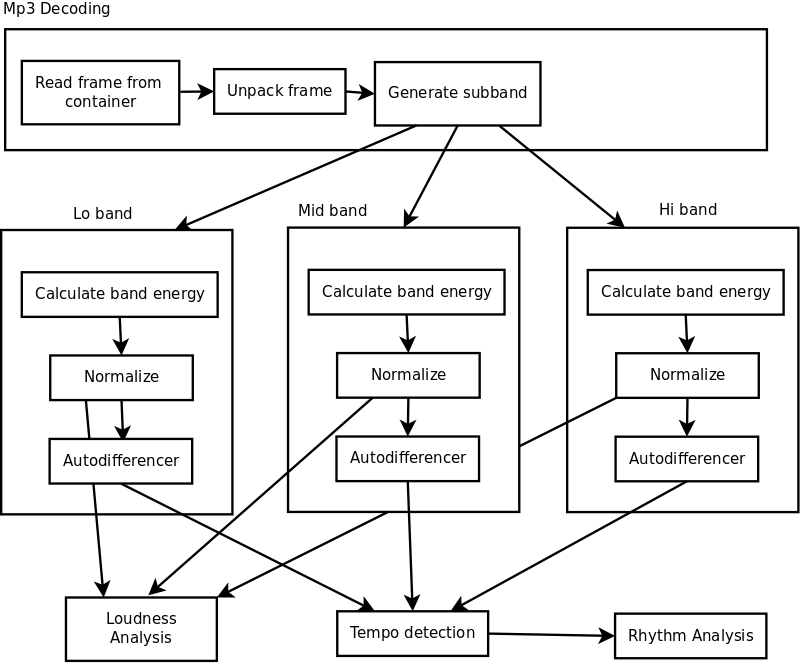
The subband data generated in the mp3 decoder is 32 samples long each time, what implies that the frequencies are spread from 0 to 22050 in 32 chunks. So every band is about 689 Hz.
With that information in hand, the next challenge consisted of approximating the old analysis routines sufficiently close so that people would not notice a qualitative difference between the old and the new routines (except for the speed of course).
To do that, we generated a chirp from 40 to 22000 Hz and ran the old analysis over it, thereby plotting the measured energy densities, we did the same for the new analysis and then determined for each subband the required gain to match the same energy as the old analysis routines.
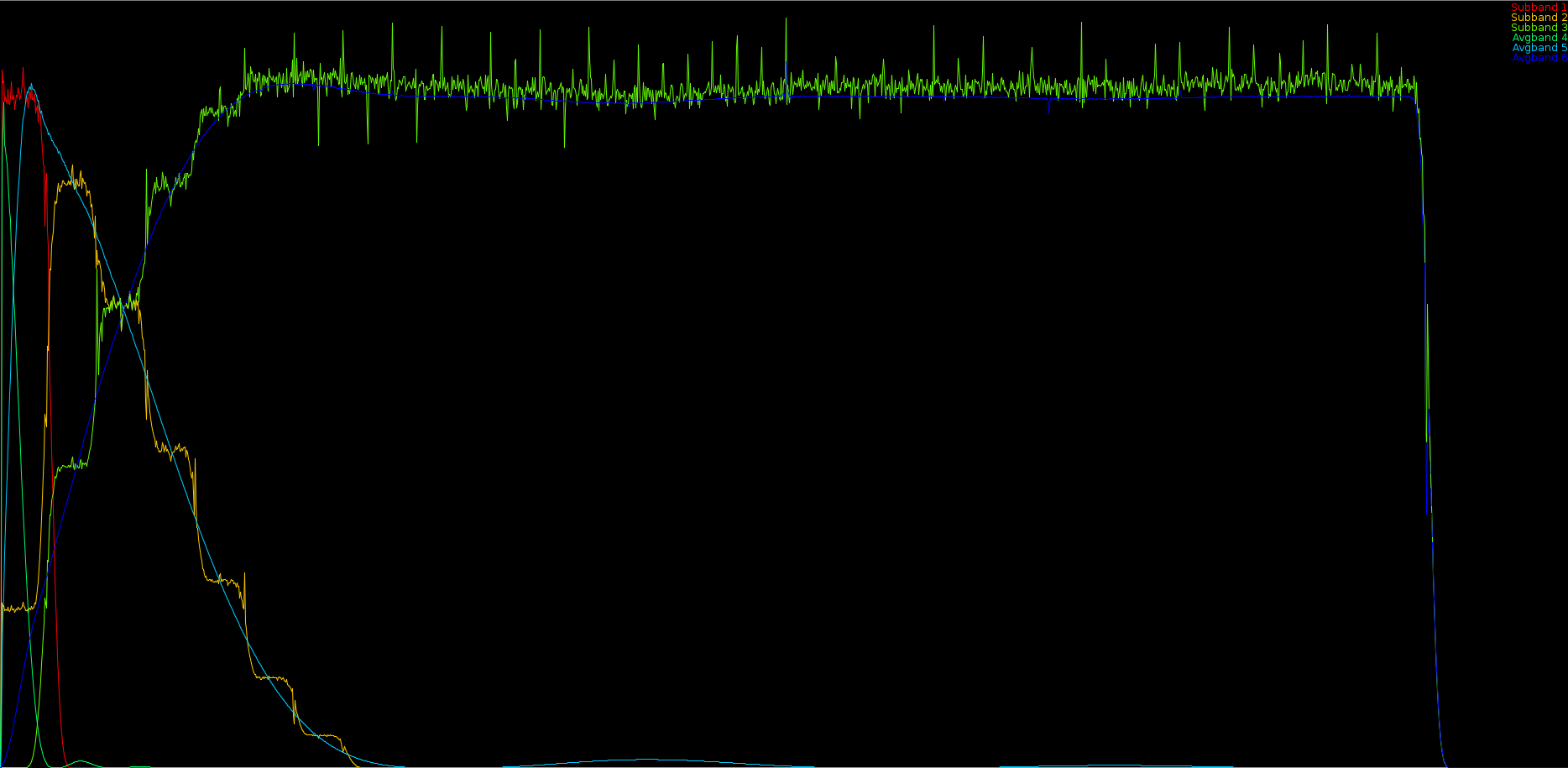
The above picture shows the expected curves (the smooth ones) and the approximated ones based on the subband info retrieved from the decoder
The result of omitting a large section of the pipeline is a speedup of about two. We could achieve larger speedups by not combining the various frequency bands, but in that case a full reanalysis of all songs would be required. Because I do not assume that users are waiting to spend another 10 hours waiting for BpmDj, this tradeoff felt like a good one.
Another 1.5x speedup
Further optimalisations included
- faster rhythm detector by avoiding to unpack lo/middle/high information. Now it requires slightly more memory but is faster
- Further optimized the javazoom library. It is quite amazing what type of 'optimalisations' those Java folks have been adding. Removed a series of pointless array copies, which improved performance another 25%
- then the decoding stage of the mp3 decoder has seen the replacement of its lookup table by a tree. (In Java array indexing is slower than field access in an object; and since it is the same number of pointers, it is better to have an explicit tree).